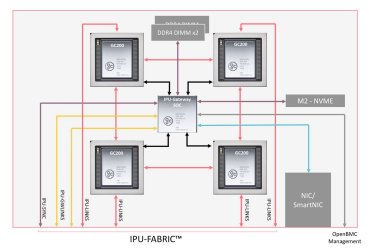
Graphcore7月正式发布第二代IPU以及用于大规模系统级产品IPU-Machine: M2000(IPU-M2000),新一代产品具有更强的处理能力、更多的内存和内置的可扩展性,可处理庞大的机器智能工作负载。
IPU-M2000是一款即插即用的机器智能刀片式计算单元,由Graphcore全新的7纳米 Colossus™ 第二代 GC200 IPU提供动力,并由Poplar™软件栈提供全面支持。其设计便于部署,并支持可扩展至大规模的系统。这款纤薄的1U刀片机可提供1个PetaFlop的机器智能计算,并集成了针对AI扩展优化的网络技术。
IPU-M2000可构建成IPU-POD64这一Graphcore全新模块化机架规模解决方案,可用于大型机器智能横向扩展,提供前所未有的AI计算可能性,以及完全的灵活性和易于部署的特性。它可以从一个机架式本地系统扩展到高度互连的超高性能AI计算设施中的1000多个IPU-POD64系统。
“随着IPU-M2000和IPU-POD64的推出,Graphcore进一步扩大了我们在机器智能领域的产品竞争优势。”Graphcore首席执行官Nigel Toon指出:“Graphcore通过技术创新实现更强有力的产品线,这些创新能够提供客户所期望的行业领先性能。对于寻求将机器智能计算添加到数据中心的客户而言,Graphcore新推出的IPU-M2000凭借其强大的算力、易于扩展的灵活性和突出的易用性,将具有很强的可行性和价值提升潜力。”
Mk1 IPU产品的用户可以确信,他们现有的模型和系统可以在这些新的Mk2 IPU系统上无缝运行。虽然第一代Graphcore IPU产品已经处于领先地位,但与之相比,第二代产品的性能还将提高8倍。
IPU-M2000的设计使客户可以在IPU-POD™配置中构建多达64,000个IPU的数据中心规模系统,提供16ExaFlops的机器智能计算能力。新的IPU-M2000甚至能够处理艰巨的机器智能训练或大规模部署工作负载。