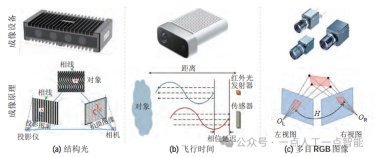
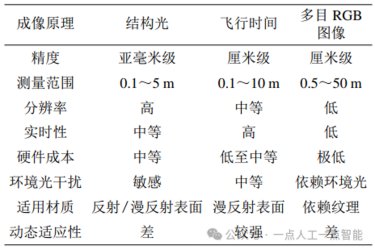
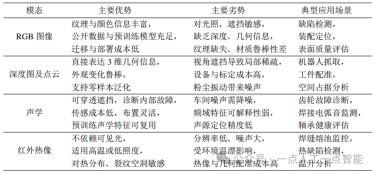
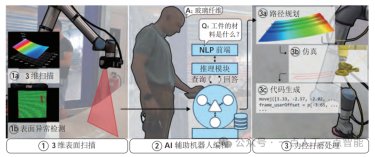
图14 低成本硬件实现精细操作[202]
2.2 可变产线柔性操作
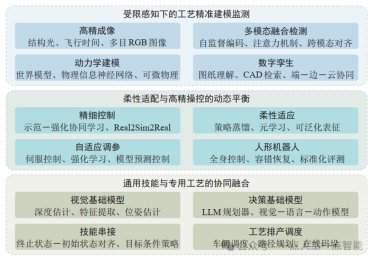
传统工业生产依赖固定产线与预设流程,适合单一产品大规模制造,但难以应对多样化和定制化需求。现代工业要求产线具备更高灵活性,依托工业之手实现快速调整与柔性操作,适配不同产品与工艺变化。本节将从通用控制策略学习、交互表征设计与决策基础模型3方面,探讨工业之手在可变产线下的柔性操作方案。
· 通用控制策略学习 通用控制策略的核心目标是学习一个策略框架,使机器人在多任务场景下快速迁移。下面从策略蒸馏和元学习2个角度阐述。
策略蒸馏法[204-205]将多个深度网络中的策略知识迁移至一个网络,使最终的合并策略在多种环境中都能表现出色。AutoMate法[206]将多个专家装配策略蒸馏到一个通用策略中,实现了在20种装配任务中的通用性。Wu等[207]提出基于师生框架的混合策略,将专家行为融合至扩散策略[208],支持超30类物体的动态抓取。Mosbach等[209]针对机器人从杂乱环境中灵巧抓取物体难题,结合强化学习与策略蒸馏两阶段学习,能够有效抓取多种物体,并展现了针对新物体的零样本迁移能力。
元学习[210]通过学习多个任务的经验,使模型能在新任务中有效利用已有知识进行快速学习和泛化。元强化学习[211]则通过多任务学习使智能体在不同环境中迅速调整策略,并通过少量经验获得良好表现。工业插入任务中的接触力学和摩擦效应难以通过传统反馈控制处理,Schoettler等[212]使用元强化学习获得仿真任务的潜在结构。
在仿真中对策略进行预训练后,通过少量现实世界试验和误差校正,快速适应工业插入任务。针对插入任务中探索成本高、成功率低和适应新任务难的问题,ODA算法[213]融合离线数据、上下文元学习与在线微调,仅用少量演示数据,通过约30 min在线训练,便可高效适应插入任务,降低探索成本并提升成功率。
· 交互表征设计 交互表征旨在提取跨任务、跨环境的通用特征,使机器人能实现快速迁移并高效应对复杂变化。通过对感知与操作之间的关联关系进行建模,提升系统的泛化与适应能力。下面从2维与3维2个方向展开介绍。
2维表征方面,可供性[214]用于定位图像中的可交互区域,作为感知与动作之间的桥梁。例如,在机器人抓取场景中,通过将可供性锚定于具体区域,可帮助模型寻找物体上最佳的抓取位置。VIMA法[215]通过预训练检测器识别目标物体并提取分割区域,引导抓取策略聚焦关键区域。Mu等[216]提出结合图像简化与深度网络的方法,优化抓取位姿,显著提升了传感器模糊和结构复杂情况下的抓取成功率。Instruct2Act法[217]则结合SAM等[118]开放物体检测模型,根据任务指令与3维坐标,生成机械臂抓取动作。
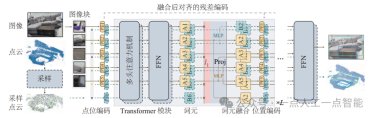
3维交互表征方面,现有工作通过设计具有足够强泛化能力的3维交互表征,提升机器人在复杂环境中的操作能力。She等[218]提出基于交互平分曲面(IBS)的状态建模方法,细粒度表达手爪与物体之间的关系,实现对复杂形状的灵巧抓取。Xiao等[219]设计末端与物体接触区域的动态表征,驱动按钉式夹爪实现自适应抓取与手内重定位。文[220] 提出跨抓手策略迁移框架,利用通用策略预测关键点位移,再由适配模块转换为具体控制信号,适配不同手爪结构。DP3方法[221]关注稀疏点云的紧凑3维表示,通过高效的点编码器提取3维视觉特征,展现出良好的泛化能力。
· 决策基础模型 决策基础模型通过在多任务、多环境中训练,学习共享特征与通用策略,具备跨任务泛化能力,突破了传统方法对单一场景的依赖。决策基础模型大致形成两条范式,分别侧重“先规划后执行”与“端到端决策”。
“先规划后执行”范式以LLM充当高层规划器,将自然语言任务指令解析为低阶技能序列,交由底层控制器执行。该方法依托LLM的世界知识与逻辑推理能力进行任务分解[222-223],具备可解释性强、模块化好、融合符号规则方便等优点,但对技能库覆盖和感知—动作接口的一致性要求较高。
PaLM-E方法[224]将图像与状态等感知输入信息编码为与文本统一的潜变量,通过LLM自注意力机制联合处理,输出语言形式的任务计划。SayCan方法[225]则结合LLM生成的候选技能与可行性评分网络,筛选出最可执行、最有效的动作序列。
Ha等[226]提出LLM引导下的扩散策略框架,通过高层任务规划与失败检测来生成多样轨迹,提升多任务策略的泛化能力。思维链(CoT)模拟人类的思考过程,将复杂问题分解为一系列更小、更易于处理的步骤[227]。Embodied-GPT方法[228]通过CoT生成更详细和可执行的计划,从而提高机器人执行任务的成功率。
在“先规划后执行”范式中,LLM负责生成任务规划与技能序列,而底层技能库通常预先定义。此时,技能衔接成为关键问题,即需确保前一技能的终止状态与后一技能的初始状态紧密匹配,以实现无缝切换[229]。
T-STAR方法[230]通过奖励正则化来优化各子任务策略,使其终止状态与起始状态尽可能重合。Huang等[231]则训练高层调度器,为每个阶段选择最可能完成衔接的目标条件策略,调度器同样通过强化学习获得。然而,多数方法依赖固定顺序的子策略重训练,难以应对生产工序的灵活调整。
DeCo方法[232]采用了一种更具实践意义的方案:为每个技能定义一个起始关键帧,每当完成当前工序后,便通过运动规划算法[233]自动转移至下一个技能的关键帧,以实现技能的自由组合。
“端到端决策”通过联合编码多模态观测信息与语言指令,直接输出低层控制信号,实现感知—理解—控制的一体化闭环[234-235]。该方法在大规模交互轨迹上训练,可零样本迁移到新物体与场景,但长时序推理与安全验证仍待突破。
LaMo方法[236]首次探索将小规模GPT-2用作离线强化学习策略,采用条件模仿学习框架进行训练。谷歌公司的Robot Transformer系列[237-238]借助更大模型和数据集,在多种具身任务中取得优异表现。OpenVLA方法[239]基于LLaMA 2[240]、DINOv2[85]与SigLIP[241],在97万条真实演示数据上训练,支持消费级GPU微调,具备多任务与语言指令泛化能力。
ManipLLM方法[242]通过微调多模态大模型,实现对末端执行器位姿的直接预测。π0.5[243]在π0[244]基础之上构建,整合异构任务数据,支持开放世界下的长时序执行。3D-VLA模型[121]融合3维场景理解与动作规划,实现了对真实物理世界的多步操作生成能力。
尽管端到端方法可借助大规模数据学习通用策略,但在复杂多样的工业任务中训练出“一劳永逸”的模型仍具挑战。更可行的路径是:以预训练策略为基础,结合少量任务数据进行高效微调,从而提升适应性并降低数据需求。
RLDG方法[245]采用强化学习策略生成高质量示范数据,再用于精细操控任务的微调流程,显著提升模型成功率约30%~50%。ConRFT方法[246]针对VLA模型面临的示范数据稀缺、分布偏差和适配困难等问题,设计了统一的离线—在线强化微调框架。
离线阶段通过少量示范数据与一致性训练初始化模型(如OCTO[247]),在线阶段结合人类干预与交互数据实现快速安全适应。在8项高接触任务中,ConRFT方法仅用45~90 min微调便将平均成功率提升至96.3%。这些方法为工业具身智能中通用策略的快速适配与部署提供了可行路径。
案例研究1:多零部件柔性装配
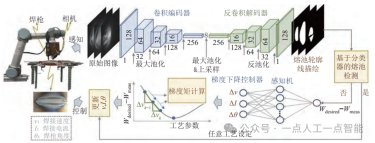
面对柔性制造多类型、多配置和个性化定制的需求,传统固定生产线通常依赖于高度定制的工程设计和固定的运动路径,难以灵活应对多样化零件的装配需求。装配中零部件结合方式的变化直接影响接合强度,机器人需要具备高度的自适应调整能力以适应各种几何形状和姿态的零部件,如图15所示,这对传统机器人控制技术提出了挑战。